La mayoría de los problemas de indexación que parecen misteriosos tienen una explicación concreta: Google visitó tu sitio, pero no dedicó suficiente tiempo a las páginas que más importan. O peor, desperdició ese tiempo en cientos de URLs que no aportan nada.
Eso es, en esencia, un problema de crawl budget.
Es uno de esos conceptos de SEO técnico que parece muy abstracto hasta que lo ves en acción en un sitio real: páginas nuevas que tardan semanas en aparecer en Google, contenido importante que nunca se indexa, ecommerce donde los productos más relevantes están por debajo de miles de URLs de filtros sin valor. Cuando entiendes cómo funciona el crawl budget, esos problemas dejan de ser misteriosos y se vuelven corregibles.
Esta guía explica qué es el crawl budget, qué lo condiciona, cómo detectar si tienes un problema y qué acciones tienen mayor impacto para optimizarlo.
En este artículo
- Qué es el crawl budget
- Los dos componentes del crawl budget
- ¿Todos los sitios deben preocuparse por esto?
- Cómo detectar si tienes un problema de crawl budget
- Qué desperdicia el presupuesto de rastreo
- Cómo optimizar el crawl budget paso a paso
- Crawl budget vs indexación: no son lo mismo
- Errores comunes que empeoran el problema
- Herramientas para analizar el crawl budget
- Preguntas frecuentes
Qué es el crawl budget
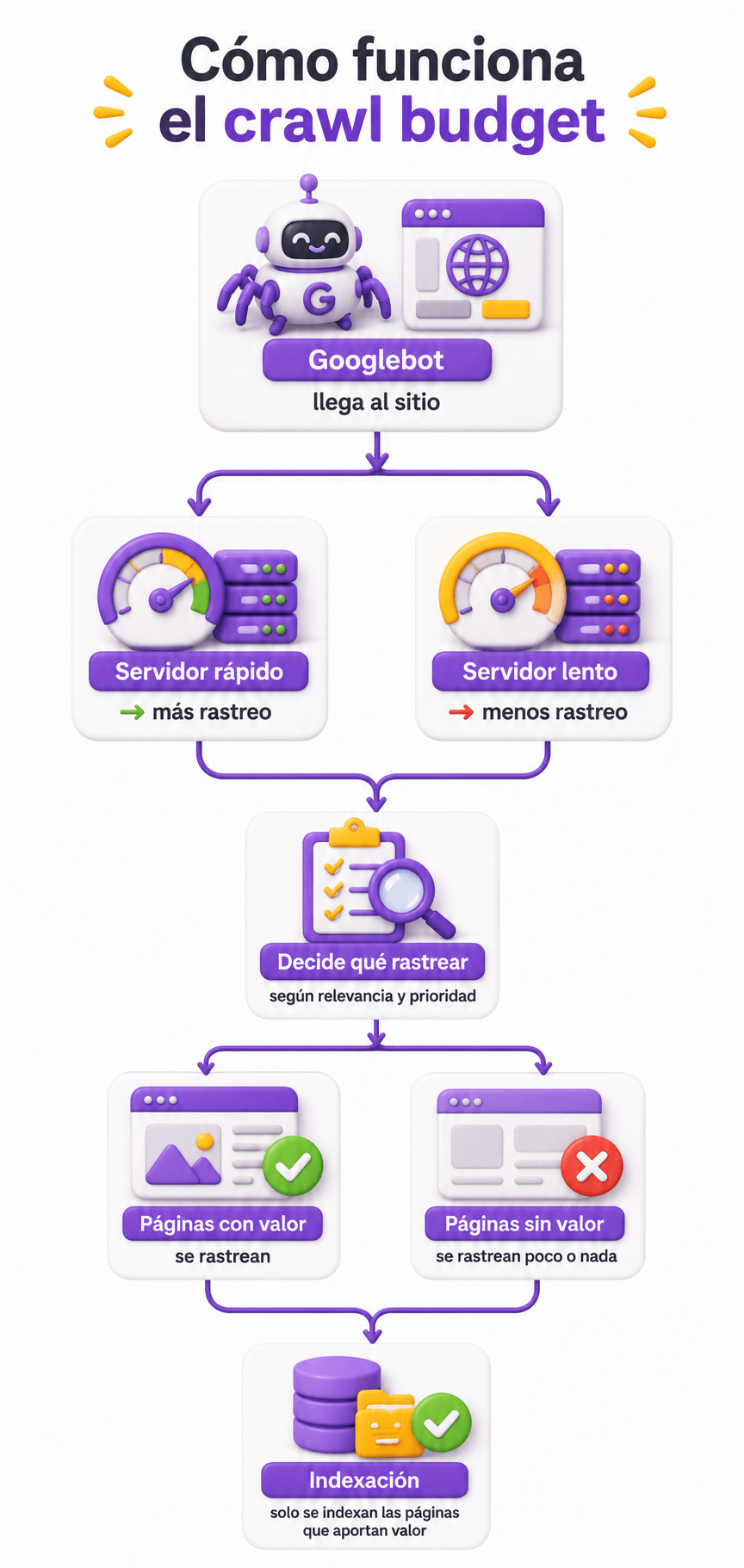
El crawl budget, o presupuesto de rastreo, es la cantidad de URLs que Googlebot puede y quiere rastrear en un sitio web durante un período de tiempo determinado.
Google no tiene capacidad ilimitada para rastrear toda la web continuamente. Sus robots de rastreo (Googlebot) tienen que repartir su tiempo y recursos entre miles de millones de páginas. Por eso cada dominio recibe una especie de “cuota” de rastreo: un número aproximado de páginas que Google va a visitar en cada ciclo.
La documentación oficial de Google Search Central sobre crawl budget define este concepto como el resultado de combinar dos factores: la capacidad de rastreo (cuánto puede rastrear Google sin sobrecargar tu servidor) y la demanda de rastreo (cuánto le interesa a Google visitar tus páginas).
Cuando ese presupuesto está bien aprovechado, Google dedica su tiempo a las páginas que importan. Cuando está mal gestionado, Googlebot llega a tu sitio y se pierde rastreando filtros de ecommerce, páginas de búsqueda interna, URLs con parámetros UTM o archivos de categorías vacíos, mientras las páginas importantes esperan.
Los dos componentes del crawl budget
Crawl Capacity Limit: cuánto puede rastrear Google
Este componente define el límite técnico de rastreo que Google se autoimpone para no sobrecargar tu servidor. Si Googlebot detecta que cada vez que visita tu sitio tarda mucho en recibir respuesta, o que el servidor devuelve errores con frecuencia, reduce su velocidad de rastreo para no empeorar la situación.
Lo que condiciona este límite es principalmente el rendimiento de tu infraestructura: tiempo de respuesta del servidor, errores 5xx (errores de servidor), timeouts y capacidad del hosting. Un servidor rápido y estable permite que Googlebot rastree más páginas en el mismo tiempo. Un servidor lento o inestable hace que Google ralentice el rastreo para no tumbarlo.
El Crawl Capacity Limit también puede ajustarse manualmente desde Google Search Console, aunque Google recomienda no tocarlo salvo en situaciones muy específicas (como una migración en marcha donde necesitas ralentizar el rastreo temporalmente para dar tiempo a que las redirecciones se estabilicen).
Crawl Demand: cuánto le interesa a Google rastrear tu sitio
El segundo componente es más estratégico. La Crawl Demand es el interés que tiene Google en visitar tus páginas, y está directamente relacionada con la percepción que Google tiene de su valor.
Google dedica más recursos de rastreo a páginas que reciben backlinks de calidad, que se actualizan con frecuencia, que generan clics en los resultados de búsqueda y que forman parte de sitios con alta autoridad de dominio. Una página nueva en un dominio con mucha autoridad puede indexarse en horas. La misma página en un dominio nuevo sin autoridad puede tardar semanas.
La Crawl Demand también aumenta cuando Google detecta que un sitio se actualiza con frecuencia. Si publicas contenido regularmente y ese contenido genera tráfico y engagement, Google visita tu sitio con más frecuencia. Si llevas meses sin actualizar nada y el tráfico es bajo, las visitas de Googlebot se espacian.
¿Todos los sitios deben preocuparse por el crawl budget?
No, y Google lo dice explícitamente en su documentación. Para sitios pequeños con pocas páginas y una arquitectura limpia, el crawl budget rara vez es un problema: Googlebot puede rastrear todo el sitio en cada visita sin ningún esfuerzo.
El crawl budget empieza a ser un factor crítico cuando se dan alguna de estas condiciones:
- El sitio tiene más de 10.000 URLs (y especialmente cuando supera las 100.000)
- Es un ecommerce con filtros de producto que generan URLs dinámicas
- Hay paginación extensa en categorías o listados
- El CMS genera URLs automáticas innecesarias (archivos de fecha, tags vacíos, páginas de autor)
- Hay parámetros de seguimiento en las URLs (UTM, parámetros de sesión) que no están controlados
- Hay evidencia en Search Console de que páginas importantes no se indexan o tardan mucho
Si tu sitio tiene 50 páginas y Search Console muestra que todas están indexadas correctamente, el crawl budget no es tu problema. Hay otros factores más urgentes donde invertir el tiempo.
Cómo detectar si tienes un problema de crawl budget
Antes de optimizar nada, hay que confirmar que el problema existe. Estas son las señales más claras y cómo verificarlas:
Señal 1: páginas nuevas que tardan semanas en indexarse
Si publicas contenido nuevo y pasan más de dos o tres semanas sin que aparezca en Google, hay un problema de rastreo o indexación. Para verificarlo, usa la herramienta de Inspección de URL en Search Console: introduce la URL y mira cuándo fue la última vez que Googlebot la visitó y si está indexada.
Señal 2: muchas URLs en estado “Descubierta, actualmente no indexada”
En el informe de Cobertura de Search Console, este estado significa que Google conoce la existencia de esas páginas (las ha descubierto a través de enlaces o el sitemap) pero ha decidido postponer su rastreo. Si tienes cientos o miles de URLs en este estado, es una señal directa de que el crawl budget no está llegando a donde debería.
Señal 3: gran discrepancia entre páginas enviadas y páginas indexadas
Si tu sitemap declara 5.000 URLs pero Search Console solo muestra 800 indexadas, hay algo que está impidiendo que Google procese el resto. Puede ser un problema de calidad del contenido, pero también puede ser un problema de crawl budget.
Señal 4: análisis de logs con rastreo concentrado en páginas irrelevantes
El análisis de los logs del servidor es la forma más precisa de ver qué hace realmente Googlebot en tu sitio. Si los logs muestran que Googlebot dedica el 70% de sus visitas a páginas de filtros, URLs con parámetros o páginas de búsqueda interna, mientras que las páginas de producto o los artículos del blog apenas reciben visitas, el presupuesto está siendo mal aprovechado.
Qué desperdicia el presupuesto de rastreo
Estos son los problemas más frecuentes que hacen que Googlebot pierda tiempo en páginas que no aportan valor:
URLs con parámetros no controlados
Es el problema más común en ecommerce y sitios con buscador interno. Cuando los filtros de producto o los parámetros de búsqueda generan URLs únicas, el resultado puede ser una explosión de URLs casi idénticas:
/zapatos?color=negro&talla=42/zapatos?talla=42&color=negro/zapatos?color=negro&talla=42&orden=precio/zapatos?utm_source=instagram&color=negro&talla=42
Esas cuatro URLs muestran exactamente el mismo contenido, pero Googlebot las trata como páginas distintas y dedica tiempo a rastrear cada una. Multiplica eso por miles de productos y decenas de combinaciones de filtros, y tienes millones de URLs que consumen el presupuesto de rastreo sin generar ningún valor indexable.
Contenido duplicado sin gestionar
Las páginas con contenido idéntico o muy similar obligan a Google a rastrear varias versiones del mismo contenido para decidir cuál es la principal. Sin etiquetas canonical correctamente implementadas, esa decisión puede no resolverse nunca de forma óptima.
Páginas sin valor SEO que Google sigue rastreando
Páginas de resultados de búsqueda interna, carritos de compra, páginas de login, páginas de confirmación de pedido, tags de WordPress con una sola entrada, archivos de fecha vacíos: ninguna de estas páginas debería estar en el índice de Google ni consumir presupuesto de rastreo. Pero si no están bloqueadas, Googlebot las visita igualmente.
Errores 404 que reciben enlaces internos
Cada vez que Googlebot sigue un enlace y encuentra un error 404, ha gastado recursos sin resultado. Si tienes páginas eliminadas que todavía reciben enlaces internos desde otras partes del sitio, estás desperdiciando presupuesto de rastreo en cada ciclo.
Cadenas de redirecciones
Una redirección que pasa por tres o cuatro saltos antes de llegar al destino final consume más tiempo de rastreo que una redirección directa. Y un bucle de redirecciones (A redirige a B, B redirige a A) hace que Googlebot abandone sin resultado.
Arquitectura con páginas importantes enterradas en profundidad
Si tus páginas más importantes están a ocho clics de la portada, Google les asigna menos prioridad de rastreo. La profundidad de la arquitectura afecta directamente cuántos recursos dedica Googlebot a llegar hasta esas páginas.
Cómo optimizar el crawl budget paso a paso
1. Audita primero: sabe dónde se está yendo el presupuesto
Antes de bloquear o redirigir cualquier cosa, necesitas un diagnóstico. Revisa en Search Console el informe de Estadísticas de Rastreo (en Configuración) para ver cuántas páginas rastrea Google al día y qué tipo de respuestas recibe. Complementa con un rastreo de Screaming Frog para identificar qué URLs existen en tu sitio que no deberían estar expuestas a Googlebot.
Si tienes acceso a los logs del servidor, analízalos con Screaming Frog Log File Analyser o JetOctopus para ver exactamente qué hace Googlebot cuando visita tu sitio. Es la fuente de datos más precisa que existe para este tipo de análisis.
2. Controla los parámetros de URL
Para los parámetros que no generan contenido único (parámetros de seguimiento UTM, parámetros de ordenación, parámetros de sesión), tienes varias opciones:
- Implementar etiquetas canonical en todas las variantes apuntando a la URL limpia
- Usar la configuración de parámetros en Google Search Console (aunque Google ha reducido su soporte para esta función)
- Configurar el servidor para que no genere URLs únicas para esos parámetros
Para los parámetros de filtros de ecommerce que sí generan contenido diferente (como filtros por categoría o características del producto), la solución depende de si esas páginas de filtro tienen valor SEO por sí mismas. Si no lo tienen, noindex o canonical hacia la categoría principal. Si lo tienen, trabájalas como páginas propias con contenido optimizado.
3. Bloquea en robots.txt las secciones sin valor SEO
El archivo robots.txt permite indicar a Googlebot qué secciones del sitio no debe rastrear. Es la herramienta más directa para proteger el presupuesto de rastreo de páginas que nunca deberían estar en el índice:
User-agent: Googlebot Disallow: /busqueda/ Disallow: /carrito/ Disallow: /checkout/ Disallow: /mi-cuenta/ Disallow: /wp-admin/ Disallow: /feed/
Dos advertencias importantes: primero, bloquear una URL en robots.txt no la desindexa si ya está indexada, solo impide que Googlebot la rastree en el futuro. Segundo, si una URL bloqueada en robots.txt recibe backlinks externos, Google puede indexarla igualmente como URL sin contenido. Para desindexa páginas que ya están indexadas, usa noindex (que requiere que Googlebot pueda rastrear la página para leer la etiqueta).
4. Implementa canonical correctamente
La etiqueta canonical le dice a Google cuál es la versión principal de un contenido cuando existen varias URLs con el mismo o similar contenido. Es especialmente útil para:
- Páginas de filtros de ecommerce que tienen contenido similar a la categoría padre
- Versiones con y sin parámetros de una misma URL
- Páginas de paginación (aunque Google ha evolucionado en cómo maneja la paginación)
- Versiones HTTP y HTTPS, o con y sin www, si por algún motivo coexisten
5. Elimina o consolida el contenido delgado y las páginas huérfanas
Las páginas con muy poco contenido (thin content) y las páginas que no reciben ningún enlace interno son candidatas a ser eliminadas, noindexadas o consolidadas con páginas relacionadas. Cada página de baja calidad que eliminas es presupuesto de rastreo que se redirige hacia páginas que sí merecen ser indexadas.
6. Mejora la velocidad de respuesta del servidor
Un servidor que responde en menos de 200ms permite que Googlebot rastree más páginas en el mismo tiempo que un servidor que responde en 2 segundos. Las mejoras más impactantes para la velocidad de servidor suelen ser: upgrade del plan de hosting, implementación de CDN, configuración de caché a nivel de servidor y optimización de consultas a la base de datos si el tiempo de respuesta viene del backend.
7. Mantén el sitemap XML limpio y actualizado
El sitemap no mejora directamente el crawl budget, pero sí orienta a Googlebot hacia las páginas que consideras más importantes. Un sitemap limpio incluye solo URLs que están indexadas (status 200), que tienen etiqueta canonical apuntando a sí mismas y que no tienen noindex. No incluyas redirecciones, páginas con errores ni páginas excluidas del índice.
8. Reduce la profundidad de la arquitectura
Las páginas accesibles en tres clics desde la portada reciben más presupuesto de rastreo que las que están a ocho clics. Revisar la arquitectura de navegación para acercar las páginas más importantes a la raíz del sitio tiene un impacto directo en cómo Googlebot distribuye su tiempo.
Crawl budget vs indexación: no son lo mismo
Es un error frecuente confundir estos dos conceptos. Son etapas distintas del proceso y tienen soluciones distintas:
| Concepto | Qué significa | Cuándo es el problema |
|---|---|---|
| Crawl budget | Google visita o no visita la URL | Googlebot no llega a rastrear la página |
| Indexación | Google decide incluir o no la URL en su índice | Googlebot rastrea la página pero decide no indexarla por baja calidad, noindex, canonical, etc. |
Una página puede ser rastreada perfectamente y no indexarse por problemas de calidad de contenido. Y una página puede no rastrearse nunca no porque tenga problemas de crawl budget, sino porque no tiene ningún enlace interno que apunte a ella (página huérfana) y no está en el sitemap.
Antes de concluir que tienes un problema de crawl budget, descarta estas otras causas. La herramienta de Inspección de URL en Search Console te dice si la página fue rastreada, cuándo, si está indexada y si hay algún problema técnico que lo impide.
Errores comunes que empeoran el crawl budget sin que lo notes
Bloquear CSS y JavaScript en robots.txt. Google necesita renderizar tus páginas para entenderlas correctamente. Si bloqueas los archivos CSS o JS que construyen el contenido visible de tus páginas, Googlebot puede ver una versión incompleta del sitio y tomar decisiones de indexación incorrectas. Salvo razones muy específicas, no bloquees estos archivos.
Usar noindex como solución de crawl budget. El noindex no reduce el rastreo: Google sigue visitando la página para leer la etiqueta, solo decide no indexarla. Si tu objetivo es reducir el rastreo de ciertas secciones, robots.txt es la herramienta correcta. Si tu objetivo es desindexa páginas que ya están indexadas, noindex es la herramienta correcta. Son soluciones a problemas distintos.
Dejar plugins o extensiones que generan URLs automáticas sin revisar. En WordPress, plugins de caché, SEO, ecommerce o formularios pueden generar cientos de URLs adicionales sin que el propietario del sitio lo sepa. Una auditoría periódica con Screaming Frog o Sitebulb detecta estas URLs antes de que se conviertan en un problema a escala.
No corregir los errores 404 con enlaces internos. Si después de reestructurar el sitio o eliminar páginas no actualizas los enlaces internos que apuntaban a esas URLs, Googlebot sigue siguiendo esos enlaces en cada ciclo de rastreo y encontrando errores. Es presupuesto desperdiciado que se acumula.
Paginación infinita o muy profunda sin gestionar. Si tienes categorías con 200 páginas de paginación y no has decidido cómo gestionar el rastreo de esas páginas (canonical hacia la página 1, noindex en las páginas profundas, o contenido propio en cada página), Googlebot puede perderse rastreando /categoria/page/147/ mientras la página principal de la categoría no recibe suficiente atención.
Herramientas para analizar el crawl budget
Google Search Console: el punto de partida obligatorio. El informe de Estadísticas de Rastreo (en Configuración) muestra el número de páginas rastreadas por día, el tipo de respuesta (200, 301, 404, 5xx) y el desglose por tipo de archivo. El informe de Cobertura muestra el estado de indexación de todas las URLs conocidas.
Screaming Frog SEO Spider: rastreador técnico que simula cómo Googlebot ve tu sitio. Detecta URLs con parámetros, contenido duplicado, errores 404, cadenas de redirección y páginas con contenido delgado. Su módulo Log File Analyser analiza los logs del servidor para ver qué hace realmente Googlebot.
Sitebulb: alternativa a Screaming Frog con visualizaciones de arquitectura más detalladas. Especialmente útil para ver la distribución de profundidad del sitio y cómo fluye el PageRank interno.
JetOctopus: herramienta especializada en análisis de logs y crawl budget para sitios grandes. Permite cruzar datos de logs de servidor con datos de Google Search Console para identificar qué URLs está rastreando Googlebot y cuál es el estado de indexación de cada una.
Botify: plataforma enterprise para SEO técnico a gran escala. Combina análisis de logs, rastreo, datos de Search Console y analytics. Orientada a sitios muy grandes (cientos de miles o millones de URLs).
Ahrefs Webmaster Tools: gratuita para propietarios de sitios verificados. Permite detectar páginas huérfanas, errores de rastreo y problemas de indexación que pueden estar afectando al presupuesto.
Conclusión
El crawl budget no es un concepto que necesite preocuparte en todos los proyectos. Pero cuando el sitio crece, cuando aparecen problemas de indexación que no tienen explicación aparente o cuando el contenido nuevo tarda demasiado en aparecer en Google, entender cómo funciona el presupuesto de rastreo y qué lo está desperdiciando puede ser la diferencia entre una estrategia SEO que funciona y una que se estanca.
La lógica es siempre la misma: facilita el trabajo de Googlebot. Elimina el ruido, acerca las páginas importantes a la superficie, corrige los errores técnicos que consumen recursos sin resultado y asegúrate de que lo primero que Google ve cuando visita tu sitio es lo que más importa para tu negocio.
Si estás viendo problemas de indexación en tu web y no sabes exactamente dónde está el problema, en nuestro servicio de auditoría SEO técnica analizamos el estado de rastreo e indexación de tu sitio con datos reales y te decimos exactamente qué corregir primero.